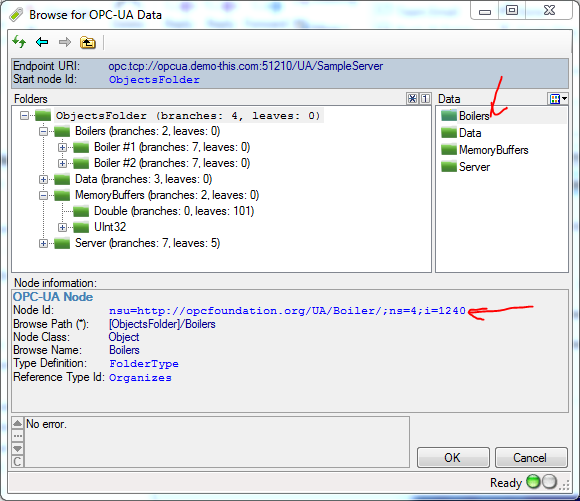
The (lower level) NodeID you are trying to browse does not seem right. For example, using the demo application and selecting the "Boilers" node, I can see that its NodeId is
nsu=http://opcfoundation.org/UA/Boiler/;ns=4;i=1240
You can omit either the "nsu" or "ns", as they both describe the namespace, so the following two should work as well:
ns=4;i=1240
nsu=http://opcfoundation.org/UA/Boiler/;i=1240
The server can use integer, string, GUID or opaque ID. In this case, at least for the Boiler node, it is an integer Id. This is dictated by the server, and the client must adapt to it. In your example, the namespace index is incorrect (2 instead of 4), and you use a string Id instead of integer Id.
If you are trying to do something like recursive browsing, simply take the NodeId (or better, the whole NodeDescriptor) from the returned browse element. Your code does not have to do with it anything, in such case. In other scenarios, it is true that you might have a requirement to "assemble" the NodeIds from their parts programmatically. In such case, you need to know what they should be - and that knowledge is specific to the server or its configuration, therefore there is no general advice as to how that should be done.
Also, have a look at what browse paths are (see the Concepts doc) - in some cases they are the right solution.
Best regards